Unlike traditional AI models, which typically handle only one form of data, Multimodal AI combines various types of input to provide a more in-depth insight and more trustworthy output. An example of this would be a multimodal system that would examine a photograph of a landscape and generate a written description of the landscape, or a written description and generate a corresponding image. This cross-modal ability renders these models extremely flexible.
In November 2022, OpenAI released ChatGPT, a text-based generative AI that was based entirely on natural language processing (NLP). That was unimodal, but OpenAI subsequently branched out into multimodal AI with products such as DALL•E, GPT-4o and, more recently, GPT-5, which introduced multimodal capabilities to ChatGPT itself.
Multimodal AI provides more accurate and contextual results by combining various data sources. It enhances the efficiency of activities such as image recognition, translation, and speech processing and minimizes errors and ambiguity. The model can use other modalities to be accurate even when one type of data is not available or unreliable.
This flexibility also improves the human-computer interaction by making it more natural and intuitive. As an example, virtual assistants are able to process not only verbal instructions but also visual ones, which results in more effective and convenient communication.
What Makes Multimodal AI Different?
Multimodal AI is based on the traditional machine learning paradigm at its core. The algorithms used to construct AI models learn data, train neural networks, and produce responses. These models are used in applications such as ChatGPT, which takes input and generates outputs, which are improved over time as new data and user feedback are added.
The difference between multimodal AI and traditional single-modal systems is that the former can process and integrate various types of data, which provides it with a considerable advantage. It is more powerful, more accurate, and more applicable to a broad variety of real-world situations because of this flexibility.
Multimodal vs. Unimodal AI
The main difference between multimodal AI and unimodal AI lies in the type of data they process.
A unimodal AI system only works with one type of data, e.g., text, images, or audio, and cannot interpret connections between different formats. As an example, a financial AI may only process business and economic data to make projections or find risks. Likewise, an image recognition model would be able to detect objects in images but would not be able to interpret other contexts through text or sound.
In contrast, Multimodal AI combines data from various sources, including video, audio, images, speech, and text, and can, therefore, create more detailed and context-rich insights. This method is more reflective of human perception and reasoning and also reveals relationships and patterns that cannot be identified by single-modal systems.
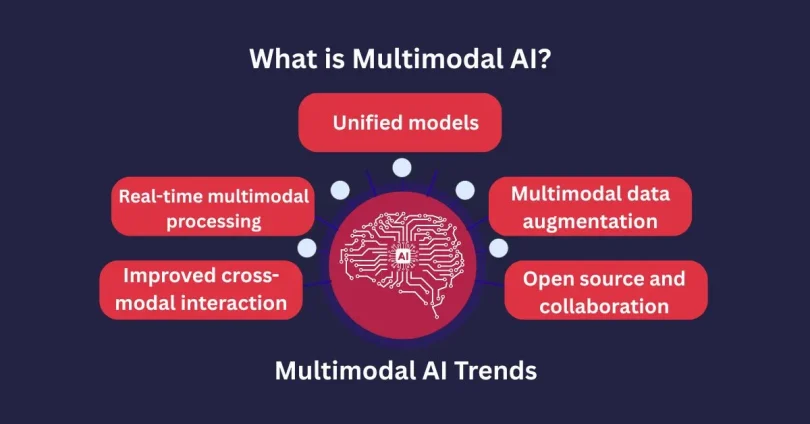
Multimodal AI Trends
It is a fast-growing field, and many trends are defining its future:
Unified models
Models such as OpenAI GPT-4 and GPT-5 with Vision and Google Gemini are built to handle text, images, and other inputs in a unified model, allowing multimodal comprehension and generation to be performed smoothly.
Improved cross-modal interaction
The latest attention mechanisms and transformer-based architectures are making the alignment and merging of different types of data more accurate and coherent.
Real-time multimodal processing
Autonomous driving and augmented reality are industries that use AI to process data in real-time, such as camera, sensor, and LIDAR data, to make split-second decisions.
Multimodal data augmentation
Scientists are developing synthetic data that combines modalities, e.g., text with images, to reinforce training and improve model performance.
Open source and collaboration
Efforts such as those of Hugging Face and Google AI are promoting collaboration by providing open-source tools that can speed up multimodal AI research and development.
The Future of Multimodal AI
s MIT Technology Review notes, disruptive products and services that are driven by multimodal AI are already on the rise and are likely to grow exponentially. The latest advancements, including the multimodal capabilities of ChatGPT, represent a transition to models that integrate the strengths of different modalities to provide more immersive user experiences.
In the future, multimodal AI will revolutionize industries such as healthcare by integrating patient records and medical imaging to offer more accurate diagnoses and treatment suggestions. The fact that it can combine various sources of data makes it an effective tool to enhance decision-making and innovation in key areas.
Multimodal AI is rapidly emerging as the next big step in artificial intelligence, the one that will fill the gap between human-like perception and machine learning. It provides more precise, context-sensitive, and multifaceted results by integrating text, image, audio, and video data to create more accurate results than traditional AI. As tech giants like OpenAI and Google continue to develop it, and as it becomes increasingly used in sectors like healthcare, finance, and autonomous systems, multimodal AI is the future of more intelligent and more intuitive technology.
Frequently Asked Questions – Multimodal AI
What is the real-life application of multimodal AI?
It is used in fields such as healthcare to integrate medical images with patient history, in autonomous vehicles to fuse sensors in real time, and in customer service with voice and visual understanding virtual assistants.
Why is multimodal AI important?
Because it mimics human perception more closely, it can capture context, reduce errors, and deliver better decision-making across industries.
What are some examples of multimodal AI models?
Popular examples include OpenAI’s GPT-5 with Vision, Google’s Gemini, and DALL·E, which integrate multiple input types for richer outputs.
What challenges does multimodal AI face?
Key challenges include the complexity of integrating large datasets, high computational requirements, and ensuring model accuracy across diverse modalities.